摘录一些《SQL 必知必会》中值得一记的内容。
Chap.1 了解 SQL
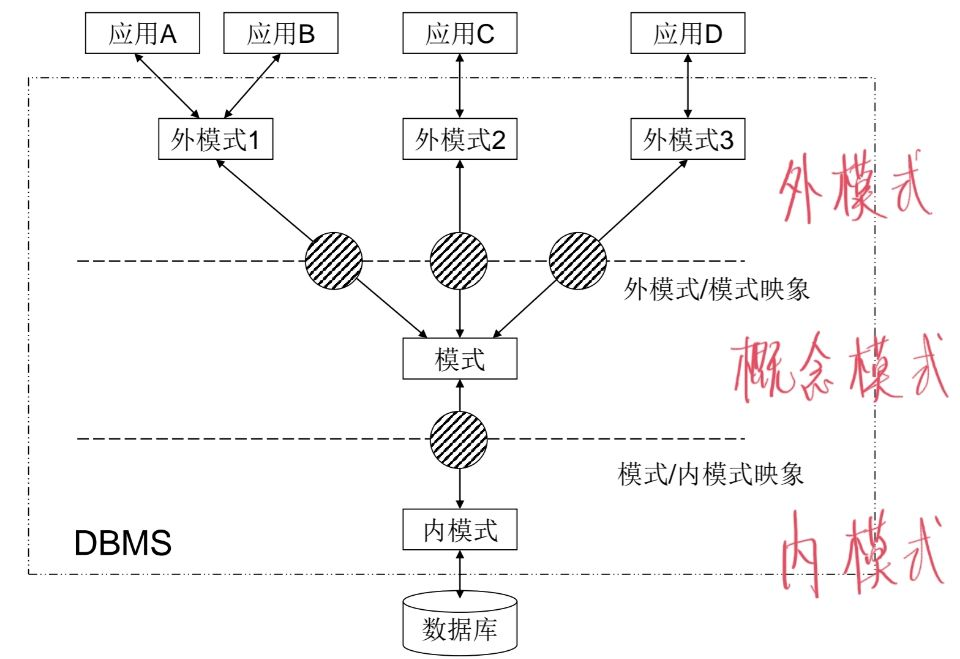
模式
表具有一些特性,这些特性定义了数据在表中的存储,包括存储什么样的数据,数据如何分解,各部分信息如何命名等信息。这些信息称作模式。
三层结构
通过三层结构,保障无论概念模式(DBMS 从 MySQL 换成 PgSQL,或者从 MySQL 换成 MongoDB)或是内模式(换服务器/硬盘了,诶~)变了,外模式(表结构)都可以不用改。
可参见浅谈数据库三大模式。
主键
- 任意两行都不具有相同的主键值
- 每一行都必须有一个主键值(主键列不允许空值NULL)
- 主键列中的值不允许修改或更新
- 主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)
外键
说是挺重要的,详见第 12 章。是不是就是说这一列的取值只能是另一列出现过的值?譬如「学生 - 选课」列只能取「课程 - 课程号」列中的某个值。
SQL 语言的注释
1 | /* |
SQL 的组成

Chap 2. 检索数据
这一课介绍如何使用 SELECT 语句从表中检索一个或多个数据列。
检索单个列
1 | SELECT column_name FROM TableName; |
检索多个列
1 | SELECT column1, column2 FROM TableName; |
检索所有列
1 | SELECT * FROM TableName; |
检索不同的值
即去重检索。
1 | SELECT DISTINCT column_name |
注意:DISTINCT 对于后面所有的列都生效(后面你就知道,有些限定关键字只对紧接着的列生效)。换言之,下面这一行语句,会对三列都进行去重检索。
1 | SELECT DISTINCT a, b, c FROM TableName; |
有人说这一句相当于:
1 | SELECT a, b, c FROM TableName group by a, b, c |
有人说实际效果是只有三列都一样才认为是一样(予以折叠)。
限制结果
我只想要一定数量的行。
1 | SELECT column_name FROM TableName LIMIT 5; |
上面这条语句只对 MySQL、PostgreSQL 等有效,对于 Oracle 等无效。
SQL 语句和大小写
- SQL 语句不区分大小写
- 约定
- SQL 关键字:大写
- 列名:小写
- 表名:首字母大写(?
Chap. 3 排序数据
这一节讲授如何使用 SELECT 语句的 ORDER BY 字句,根据需要对检索出的数据进行排序。
什么是子句
SELECT 语句、FROM 子句、ORDER BY 子句。
排序数据
默认是升序排列。降序排列在后面有写,不着急,慢慢看。
1 | SELECT prod_name FROM Products |
但其实你也可以用没有显示出来的列进行排序:
1 | SELECT prod_name FROM Products |
注意:ORDER BY 字句必须位于 SELECT 语句的最后面。
按多个列排序
先按价格升序排,再按名字字母顺序升序排。
1 | SELECT id, price, name FROM Products |
按结果显示的列位置排序
1 | SELECT id, price, name FROM Products |
和上面的排法一样:先按价格升序排,再按名字字母顺序升序排。
老子要降序排列
按照价格降序排列。
1 | SELECT id, price, name FROM Products |
按照价格降序,价格一样的按照名字升序。
1 | SELECT id, price, name FROM Products |
1 | SELECT id, price, name FROM Products |
按照价格降序,价格一样的按照名字降序。
1 | SELECT id, price, name FROM Products |
Chap 4. 筛选数据
使用 SELECT 语句的 WHERE 子句。
使用 WHERE 子句
1 | SELECT name, price FROM Products |
另外,正如之前所言,ORDER BY 子句要丢最后,意味着要用就得这么用:
1 | SELECT name, price FROM Products |
WHERE 子句操作符
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| <> / != | 不等于 |
| !< | 不小于 |
| !> | 不大于 |
| BETWEEN | 在指定的两个值之间 |
| IS NULL | 为 NULL 值 |
范围值检查
1 | SELECT name, price FROM Products |
Chap 5. 高级数据过滤
这一课讲授如何组合 WHERE 子句以建立功能更强、更高级的搜索条件。我们还将学习如何使用 NOT 和 IN 操作符。
AND 和 OR
逻辑操作符:AND 和 OR。
1 | SELECT id, price, name |
顺序
优先处理 AND 操作符,再处理 OR。当然,你可以用括号。
IN
1 | SELECT name, price FROM Products |
其实用 OR 也能实现
1 | SELECT name, price FROM Products |
但相比用一连串的 OR,IN 的最大优点是可以包含其他 SELECT 语句。详见 Chap. 11。
NOT
1 | SELECT name, price FROM Products |
注意,而不是 NOT IN!是 NOT {column} IN,别的也一样:NOT {column} = 1。
Chap 6. 用通配符进行过滤
有点像正则表达式。
LIKE操作符。- 其实它在技术上应该称作「谓词」
- 百分号
%:任意字符出现任意次数
1 | SELECT id, name FROM Products |
找出以 Fish 打头,后面内容随意的 name。
- 下划线
_:任意字符出现一次 - 方括号
[ABC]:匹配字符集 A/B/C 中的一个字符一次。[^ABC]:除了 ABC 以外的
1 | SELECT name FROM users |
结果如下:
1 | name |
Chap 7. 创建计算字段
计算字段
其实就是一个虚拟列,使用其他列的数据经过拼接、变换等计算操作后得到的。计算字段是运行时(Runtime)在 SELECT 语句执行时创建的,从客户端看,计算字段的数据返回方式和其他列的数据返回方式相同。
本章概览
TRIM():去掉字符串左右两边的空格LTRIM()、RTRIM()
AS:给计算字段赋一个别名
拼接字段
感受世界的参差!(逃
Microsoft SQL Server 用 + 号:
1 | SELECT name + '(' + country + ')' |
DB2、Oracle、PostgreSQL、SQLite 用 || 号:
1 | SELECT name || '(' || country || ')' |
MySQL、MariaDB 用 Concat 函数:
1 | SELECT Concat(name, '(', country, ')') |
别名
1 | SELECT name || '(' || country || ')' AS display_name |
算术计算
1 | SELECT quantity*price AS total_price |
Chap 8. 使用函数处理数据
难过的是,几乎每个系列的 DBMS 都有自己的一套函数体系,所以涉及这部分的 SQL 代码不具备通用性(即不可移植)。
匹配发音相似的单词
这个放上来就图一乐,正经人谁用这玩意啊
1 | SELECT name FROM Customers |
输出:
1 | name |
日期与时间
Oracle 下找出 2020 年全年的订单:
1 | SELECT order_num |
数值处理函数
| 函数 | 说明 |
|---|---|
| ABS() | 绝对值 |
| SIN() | 正弦 |
| EXP() | 指数 |
| PI() | $\pi$ |
| SQRT() | 开方 |
Chap 9. 汇总数据
聚集函数
其实就是获取一些统计量,平均值什么的。
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | |
| MIN() | |
| SUM() | 返回某列值之和 |
AVG() 函数
全部商品的平均价格:
1 | SELECT AVG(price) AS avg_price |
某一特定品牌的商品平均价格:
1 | SELECT AVG(price) AS avg_price |
注:AVG() 函数忽略值为 NULL 的行。
COUNT() 函数
两种使用方式:
- 使用
COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值 NULL 还是非空值。 - 使用
COUNT(column)对特定列中具有值的行进行计数,忽略 NULL 值的行。
有多少用户?
1 | SELECT COUNT(*) AS num_users |
有多少用户绑了手机的?
1 | SELECT COUNT(phone_number) AS num_users_with_phone |
SUM() 函数
酱瓜一共氪了多少钱?
1 | SELECT SUM(money) AS total_kejin |
酱瓜一共买了多少钱?
1 | SELECT SUM(quantity*price) AS total_price |
去重后取平均
假设每个人工资都不一样,但有些同学提交了多次,所以需要统计去重后 UX 团队的平均工资。
1 | SELECT AVG(DISTINCT salary) AS avg_salary |
DISTINCT 称为「聚集参数」。
DISTINCT 不能用于 COUNT(*),或者说,DISTINCT 不能用于计算或表达式。
Chap 10. 分组数据
涉及 GROUP BY 和 HAVING,它们都是 SELECT 语句的子句。
- 如何使用 GROUP BY 子句对多组数据进行汇总计算,返回每个组的结果。
- 如何使用 HAVING 子句过滤特定的组。
- ORDER BY 和 GROUP BY 之间的差异。
- WHERE 和 HAVING 之间的差异。
什么是分组
这个分组有点类似 Excel 里面选一列,然后点「筛选」。
之前提到:酱瓜一共氪了多少钱?
1 | SELECT SUM(money) AS total_kejin |
用分组能实现:每个用户分别氪了多少钱?
1 | SELECT username, SUM(money) AS total_kejin |
输出:
1 | username total_kejin |
按照多列来分组
先按 SELECT 出来的第二列分组,再按第一列分组:
1 | GROUP BY 2, 1 |
若 GROUP BY 後面指定兩個以上的欄位時,則要符合所有欄位值皆相同資料才會被分為一組。
过滤分组
- 不能用 WHERE:WHERE 过滤的是行而不是分组。
- 用 HAVING 子句:甚至于所有能写成 WHERE 的情况都能用 HAVING 代替。
- WHERE 过滤行,HAVING 过滤分组。
- 或者你可以这么理解
- WHERE 先过滤后分组,所以 WHERE 完以后会少掉一些行
- HAVING 先分组后过滤,所以 HAVING 完以后会少掉一些分组
- WHERE 排除的行将不包括在分组中。这可能会改变计算值,从而影响 HAVING 子句中基于这些值过滤掉的分组。
列出所有至少有两个订单的顾客:
1 | SELECT customer_id, COUNT(*) AS order_count |
列出具有两个以上高价产品的供应商,其中高价产品指产品价格 ≥ 5000:
1 | SELECT vendor_id, COUNT(*) AS num_prods |
这段话的执行顺序是:先把价格大于 5000 的产品信息行抽出来放在一个新表里面,在这个新表里面再按照供应商 ID 分组,然后再选出产品数不少于2的供应商。
分组,然后输出时记得排序
就是加上 ORDER BY 子句。
一个订单可以订多个商品。检索订了≥3个商品的订单,并且按照商品数量升序排列。
1 | SELECT order_id, COUNT(*) AS item_count |
输出:
1 | order_id item_count |
小结:SELECT 子句顺序
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | Yes |
| FROM | 从中检索数据的表 | 仅在从表中选择数据时使用。* |
| WHERE | 行级过滤 | No |
| GROUP BY | 分组说明 | 仅再按组计算聚集时使用。 |
| HAVING | 组级过滤 | No |
| ORDER BY | 输出时的顺序 | No |
*:如果你只是测试一下比如集聚函数或者TIME()之类的就可以不用。
Chap 11. 使用子查询
子查询就是嵌套在其他查询中的查询,就是指 SELECT 里面嵌套的那些个小 SELECT。
利用子查询进行过滤
与 IN 关键字相关:你这个元素在不在某个集合里面?
本书的数据库表均为关系表。订单存储在两个表中。
Order 表:
订单编号 顾客 ID 订单日期 OrderItems 表:
订单编号 订单内的物品 用户信息存在 Customers 表中:
顾客 ID 昵称 密码 地址
列出所有订购了 iPhone13 的顾客的地址。分解动作应该是:
- 检索包含物品 iPhone13 的所有订单的编号
- 检索具有前一步骤列出的订单编号的所有顾客的 ID
- 检索前一步骤返回的所有顾客 ID 的顾客信息(就是他们的地址)
对应 SQL 语句就是:
1 | # 检索包含物品 iPhone13 的所有订单的编号 |
输出:
1 | order_num |
1 | # 检索具有前一步骤列出的订单编号的所有顾客的 ID |
输出:
1 | cust_id |
1 | # 检索前一步骤返回的所有顾客 ID 的顾客地址 |
当然,实际上我们会把这三句合一(三句简一句):
1 | # 列出所有订购了 iPhone13 的顾客和地址 |
注意:
- 作为子查询的 SELECT 语句只能查询单个列,若试图检索多列将报错。这点其实很好理解,cust_id IN (…) 的 … 应该就是一个 cust_id 的列表;如果有两个 IN,你应该用
(a IN A) AND (b IN B)而非a, b IN (A, B),a, b IN (A, B)的写法是令人费解的。 - 使用子查询并不总是执行这类数据检索的最有效方法,具体请参阅第12章:JOIN语句。
子查询作为计算列
即:子查询一个计算字段,作为结果的一列。
1 | SELECT cust_name, -- 客户姓名 |
上述语句引入了一个新概念,叫「完全限定列名」,它同时指定了表名和列名。
1 | WHERE Orders.cust_id = Customers.cust_id |
Chap 12. 联结表
本章将全文摘录。
联结
SQL 最强大的功能之一就是能在数据查询的执行中联结(join)表。联结是利用 SQL 的 SELECT 能执行的最重要的操作,很好地理解联结及其语法是学习 SQL 的极为重要的部分。
在能够有效地使用联结前,必须了解关系表以及关系数据库设计的一些基础知识。下面的介绍并不能涵盖这一主题的所有内容,但作为入门已经够了。
关系表
理解关系表,最好是来看个例子。
有一个包含产品目录的数据库表,其中每类物品占一行。对于每一种物品,要存储的信息包括产品描述、价格,以及生产该产品的供应商。
现在有同一供应商生产的多种物品,那么在何处存储供应商名、地址、联系方法等供应商信息呢?将这些数据与产品信息分开存储的理由是:
- 同一个供应商生产的每个产品,其供应商信息都是相同的,对每个产品。重复此信息既浪费时间又浪费存储空间
- 供应商信息发生变化,例如供应商迁址或电话号码变动,只需修改一次即可
- 如果有重复数据(即每种产品都存储供应商信息),则很难保证每次输入该数据的方式都相同。不一致的数据在报表中就很难利用。
关键是,相同的数据出现多次决不是一件好事,这是关系数据库设计的基础。关系表的设计就是要把信息分解成多个表,一类数据一个表。各表通过某些共同的值互相关联(所以才叫关系数据库)。
在这个例子中可建立两个表:一个存储供应商信息,另一个存储产品信息。Vendors 表包含所有供应商信息,每个供应商占一行,具有唯一的标识。此标识称为主键(primary key),可以是供应商ID或任何其他唯一值。
Products 表只存储产品信息,除了存储供应商 ID(Vendors 表的主键)外,它不存储其他有关供应商的信息。Vendors 表的主键将 Vendors 表与 Products 表关联,利用供应商 ID 能从 Vendors 表中找出相应供应商的详细信息。
这样做的好处是:
- 供应商信息不重复,不会浪费时间和空间;
- 如果供应商信息变动, 可以只更新Vendors表中的单个记录, 相关表中的数据不用改动;
- 由于数据不重复,数据显然是一致的,使得处理数据和生成报表更简单。
总之,关系数据可以有效地存储,方便地处理。因此,关系数据库的可伸缩性远比非关系数据库要好。
可伸缩性
能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称为可伸缩性好(scale well)。
为什么使用联结
如前所述,将数据分解为多个表能更有效地存储,更方便地处理,并日可伸缩性更好。但这些好处是有代价的。
如果数据存储在多个表中, 怎样用一条 SELECT 语句就检索出数据呢?
答案是使用联结。简单说,联结是一种机制,用来在一条 SELECT 语句中关联表,因此称为联结。使用特殊的语法,可以联结多个表返回一组输出,联结在运行时关联表中正确的行。
创建联结
创建联结非常简单,知道要联结的所有表以及关联它们的方式即可。下面的例子创建了一个自然联结:
1 | SELECT vend_name, prod_name, prod_price |
其实就是在 Vendors × Products 这个笛卡儿积里面取出 Vendors.vend_id = Producs.vend_id 的那些行,并且结果表只有一个 vend_id 列。
如果有两个 vend_id 列,那就不是自然联结,而是等值联结。
笛卡儿积:由没有联结条件的表关系返回的结果为笛卡儿积(即没有
WHERE xx = yy的联结查询)。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。有时,返回笛卡儿积的联结,被称为叉联结(cross join)
内联结
内联结,又称等值联结,这种联结基于两个表之间的相等测试。
上面一节介绍了一种简单的等值语法:
1 | SELECT vend_name, prod_name, prod_price |
但其实ANSI SQL规范推荐的内联结方式是下面这样的:
1 | SELECT vend_name, prod_name, prod_price |
联结多个表
1 | SELECT prod_name, vend_name, prod_price, quantity |
上面的例子是要显示订单 20007 中的物品。
下面,我们回顾一下Chap 11中的一个例子,现在需要查询订购了 iPhone 13 的顾客列表。
1 | SELECT cust_name, cust_address |
前面也说过,子查询并不总是执行复杂 SELECT 操作的最有效方法,换用联结重写之:
1 | SELECT cust_name, cust_address |
Chap S1. 别名
SQL 中可以给列(包括计算列)和表起别名。其中,Oracle 数据库没有 AS 关键字,直接拍个空格即可(即 Customers AS C 写作 Customers C)。
列别名
Chap. 7
1 | SELECT RTRIM(vend_name) + '(' + RTRIM(vend_country) + ')' |
表别名
1 | SELECT cust_name, cust_address |
需要注意,表别名只在查询执行中使用,不会返回到客户端——这里和列别名不一样,列别名是会传回客户端的。
使用表别名的情况:
- 缩短 SQL 语句
- ==允许在一条 SELECT 语句中多次使用相同的表==
Chap 13. 创建高级联结
自联结
自联结 Self-join,即同一个表“自交”。
现在有一张 URC 校友联系表,需要给和酱瓜同一个公司的 URC 校友发一封邮件。
你可以用子查询:先找到酱瓜工作的公司,然后找出在该公司工作的 URC 校友。
1 | SELECT alumnus_id, name, now_company |
以上方式挺符合直觉的。不过 SQL 处理联结的速度比处理子查询要快一些,我们可以换用联结看看。
1 | SELECT A.alumnus_id, A.name, A.now_company |
其实就是:
| ID | 姓名 | 当前单位 | ID | 姓名 | 当前单位 |
|---|---|---|---|---|---|
| 1 | Jonb | Fantuan Corp. | 1 | Jonb | Fantuan Corp. |
| 1 | Jonb | Fantuan Corp. | 2 | Lisa | Fantuan Corp. |
| 1 | Jonb | Fantuan Corp. | 3 | JiangGua | Fantuan Corp. |
| 2 | Lisa | Fantuan Corp. | 1 | Jonb | Fantuan Corp. |
| 2 | Lisa | Fantuan Corp. | 2 | Lisa | Fantuan Corp. |
| 2 | Lisa | Fantuan Corp. | 3 | JiangGua | Fantuan Corp. |
| 3 | JiangGua | Fantuan Corp. | 1 | Jonb | Fantuan Corp. |
| 3 | JiangGua | Fantuan Corp. | 2 | Lisa | Fantuan Corp. |
| 3 | JiangGua | Fantuan Corp. | 3 | JiangGua | Fantuan Corp. |
自然联结
自然联结不允许一个同样意思的列出现多次。咋搞呢?系统不会帮忙的,你得自己搞。自己去删掉多余的列、或者手动只选出独特的列(一般是对第一个表用通配符 SELECT * 选所有列,而对其它表显式地指定 SELECT 哪些列)。
1 | SELECT C.*, O.order_num, O.order_date, OI.prod_id, OI.quantity, OI.item_price |
但其实,我们可能一辈子都用不到不是自然联结的等值联结——因为不是自然联结的等值联结是令人费解的。
外联结
现在有两张表,一张是老师和开课的对应表,一张是学生和选课的对应表,现在想看看每门课有谁选,包括这门课没人选你也得给我显示出来。内联结做不了这件事(学生选课表里面压根就没出现你这老师,咋 SELECT ?!),得出动外联结。
左外联结 LEFT OUTER JOIN,即 Students 主动接近 Teachers:
1 | SELECT Teachers.class_id, Teachers.name, Students.name |
得到:
| 班级号 | 老师 | 学生 |
|---|---|---|
| MAS.01 | 酱瓜 | Lisa |
| MAS.01 | 酱瓜 | Jonb |
| MAS.02 | ~rui | NULL |
看到那个 NULL 了吗,意思就是 ~rui 老师的课就 nmd 没人选。被贴贴的“主表”的所有行至少会出现一次,“舔狗”表如果没有对应能联结上的值,那这一行就填个 NULL。
当然你也可以右外联结 RIGHT OUTER JOIN。
1 | SELECT Teachers.class_id, Teachers.name, Students.name |
或者全外联结 FULL OUTER JOIN,那这样两边都可能出现 NULL 了。
1 | SELECT Teachers.class_id, Teachers.name, Students.name |
包含聚集函数的联结
检索所有顾客和每个顾客所下的订单数:
1 | SELECT Customers.id, |
这条 SELECT 语句使用 INNER JOIN 将 Customers 和 Orders 表相关联。GROUP BY 子句按照顾客分组数据,所以COUNT()函数可以对某一顾客的订单进行计算,并作为 order_count 返回。
| 顾客编号 | 订单总数 |
|---|---|
| Jonb | 4 |
| Lisa | 0 |
| JiangGua | 3 |
Chap 14. 组合查询
本章讲述如何利用 UNION 操作符将多条 SELECT 语句组合成一个结果。
组合查询
组合查询即执行多个查询(多条 SELECT 语句),并将结果作为一个查询结果集返回。你可以理解为将多个查询的结果取了一个并集,有时也称为复合查询。
主要有两种情况需要用到组合查询:
- 在一个查询中从不同的表返回结构数据;
- 对一个表执行多个查询,按一个查询返回数据。
组合查询和多个 WHERE 条件
多数情况下,组合相同表的两个查询所完成的工作与具有多个 WHERE 子句条件的一个查询所完成的工作相同。换言之,任何具有多个 WHERE 子句的 SELECT 语句都可以作为一个组合查询,在下面可以看到这一点。
创建组合查询
查询 P10、P11、P12 位阶的高层管理人员和所有 Jonbgua Labs 的成员(不论位阶是多少)。
使用 WHERE 完成:
1 | SELECT name |
使用 UNION 完成:
1 | SELECT name |
在这个简单的例子中,使用 UNION 可能比使用 WHERE 更复杂。但对于较复杂的过滤条件、或者从多个表中检索数据时,UNION 能使代码更直观。
UNION 规则
- UNION 中的每个查询必须包含相同的列、表达式或聚集函数。不过各个列不需要以相同的次序列出。
- 列数据类型必须兼容:类型不必完全相同,但必须是 DBMS 可以隐含转换的类型,例如不同但都是数值类型、或不同但都是日期类型。
关于 UNION 的列名
如果结合 UNION 使用的 SELECT 语句遇到不同的列名,那么会返回什么名字呢?比如如果一条语句是
SELECT prod_name,另一条是SELECT productName,那么查询结果返回的是什么名字呢?答案是它会返回第一个名字,本例中就是 prod_name。你可以对第一个名字定义别名,那这样就可以自定义返回的列名了。
这个行为会导致你如果需要排序也得用第一次出现的列名。上例中,
ORDER BY prod_name是合法的,但ORDER BY productName是非法的。
包含或取消重复的行
UNION 由于是取并集,所以默认会去重。你如果不希望它去重,你就用 UNION ALL 吧。
对组合查询结果排序
SELECT 语句的输出用 ORDER BY 子句排序。在用 UNION 组合查询时,只能使用一条 ORDER BY 子句,它必须位于最后一条 SELECT 语句之后。对于结果集,不存在用一种方式排序一部分、而又用另一种方式排序另一部分的情况——这种情况令人费解。因而不允许使用多条 ORDER BY 子句。
还是上面那个例子:
1 | SELECT name |
其它集合运算
有些 DBMS 支持除 UNION(取并集) 之外的集合运算,分别是 MINUS 和 INTERSECT。
- MINUS / EXCEPT:集合减法
- INTERSECT:取交集
即便不支持,你也可以用 SELECT .. WHERE .. 的方式自行实现。
Chap 15. 插入数据
本章介绍如何使用 INSERT 语句将数据插入表中。
数据插入
数据插入有以下几种情况:
- 插入完整的一行
- 插入行的一部分(某些列)
- 插入某些查询的结果
插入完整的一行
你大可以省略列名,直接按顺序插入一行。需要注意的是,各列必须按照它们在表的定义中出现的次序填充。
1 | INSERT INTO Employees |
虽然这种语法很简单,但并不安全,应该尽量避免使用。上面的SQL语句高度依赖于表中列的定义次序,万一服务端的表格式改了但你客户端代码没改,你这个顺序就寄了。
所以更推荐的方式是:
1 | INSERT INTO Employees( |
插入行的一部分
1 | INSERT INTO Employees( |
这样的话,办公室、部门、手机三列将被自动设为缺省值(NULL 或者别的)。
注意:省略列
如果表的定义允许,则可以在 INSERT 操作中省略某些列。省略的列必须满足以下两个条件之一:
- 该列定义为允许 NULL 值
- 在表定义中给出了默认值(缺省值)
但如果表中的对应列不允许有缺值,但你又省略了它的值,那就会报错。
插入检索出的数据
你可以利用 INSERT 将 SELECT 语句的结果插入表中,有人把这个操作称为 INSERT SELECT。
一般的 INSERT 一次只插入一行,但 INSERT SELECT 可以把 SELECT 出来的所有行一下子全插进去。
1 | INSERT INTO Customers( |
INSERT SELECT 中的列名
DBMS 一点也不关心 SELECT 返回的列名。它只使用了列的位置。所以 SELECT 中的第一列将被用来填充表列中指定的第一列,以此类推。
复制表
创建一个新表 EmployeeCopy,并将 Employees 表的所有内容导进去:
1 | CREATE TABLE EmployeeCopy AS SELECT * FROM Employees; |
你当然也可以只导入部分的列:
1 | CREATE TABLE EmployeeCopy AS |
SQL Server
对于 SQL Server,是用 SELECT INTO 来复制表的:
1 | SELECT * INTO EmployeeCopy FROM Employees; |
注意,在使用 SELECT INTO 时,需要知道一些事情:
- 任何 SELECT 选项和子句都可以使用,包括 WHERE 和 GROUP BY;
- 可利用联结从多个表插入数据;
- 不管从多少个表中检索数据,数据都只能插入到一个表中。
小结
这一章介绍如何将行插入到数据库表中。我们学习了使用 INSERT 的几种方法,为什么要明确使用列名,如何用 INSERT SELECT 从其它表中导入行,如何用 SELECT INTO 将行导出到一个新表。下一章将讲述如何使用 UPDATE 和 DELETE 更新和删除行。
Chap 16. 更新和删除数据
本章介绍如何利用 UPDATE 和 DELETE 语句进一步操作表数据。
更新数据
本节将分别介绍两种使用 UPDATE 语句的方式:
- 更新表中的特定行
- 更新表中的所有行
基本的 UPDATE 语句由三部分组成,分别是:
- 要更新的表
- 列名和它们的新值
- 确定要更新哪些行的筛选条件
一条基本的 UPDATE 语句如下,它一下子就改了一行的两列。
1 | UPDATE Employees |
如果你想改所有行的某一列,把 WHERE 去掉即可。
在 UPDATE 语句中使用子查询
UPDATE 语句中可以使用子查询,即:用 SELECT 语句检索出的数据来更新列数据。请参见 Chap 11.
删除数据
1 | DELETE FROM Employees |
外键与 DELETE
Chap 12 介绍了联结,简单联结两个表只需要这两个表中的公用字段。也可以让 DBMS 通过使用外键来严格实施关系(这些定义在附录 A 中)。存在外键时,DBMS 使用它们实施引用完整性。例如要向 Products 表中插入一个新产品,DBMS 不允许通过位置的供应商 ID 插入它,因为 vend_id 列时作为外键连接到 Vendors 表的。那么,这与DELETE 有什么关系呢?使用外键确保引用完整性的一个好处是,DBMS 通常可以防止某个关系需要用到的行。例如,要从 Products 表中删除一个产品,而这个产品用在了 OrderItems 的已有订单中,那么 DELETE 语句将抛出错误并终止。这是总要定义外键的另一个理由。
快速清空表
如果想从表中删除所有行,不要使用 DELETE。可以使用 TRUNCATE TABLE 语句,它速度更快:因为不记录数据的变动。
更新和删除的指导原则
在实践中,SQL Coder 应遵守以下规则:
- 除非确实打算更新和删除所有行,否则绝对不要使用不带 WHERE子句的UPDATE或DELETE。
- 保障每个表都有主键,尽可能在WHERE子句中用主键来锁定某行。
- 在 UPDATE 或DELETE前,用SELECT语句先看看这一行是不是就是目标行
- 使用强制实施引用完整性的数据库:它们不允许删除那些与其它表有关联的行。
更多内容请参阅《数据库入门:从删库到跑路》(bs
Chap 17. 创建、更改、删除表
创建表
1 | CREATE TABLE Products |
更新表
无非就是增加列/删除列。DBMS 们一般都支持增加列,但未必支持删除列。
1 | ALTER TABLE Vendors |
1 | ALTER TABLE Vendors |
如果 DBMS 不支持删除列,那就只能这么搞了:
- 用新的列布局建一个新表。
- 用 INSERT SELECT 语句从旧表复制数据到新表。有必要的话,可以使用转换函数和计算字段。
- 检验包含所需数据的新表
- 重命名旧表
- 用旧表的名字重命名新表
- 根据需要,重新创建触发器、存储过程、索引和外键
删除表
1 | DROP TABLE Cust_copy; |
重命名表
每个 DBMS 大不相同,请查对应的文档吧。
Chap 18. 使用视图
视图
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
视图可以用来简化 SQL 语句,比如 Chap 12. 中曾出现这么一个查询:
1 | SELECT cust_name, cust_address |
但如果我们能把 Customers, Orders, OrderItems 三个表的自然联结做成一个虚拟表 Product_Customer,那岂不是直接:
1 | SELECT cust_name, cust_address |
就能查到另一个产品的信息了?
为什么要使用视图
- 重用 SQL 语句
- 简化复杂的 SQL 操作。在编写查询后,可以方便地重用它而不必知道其基本查询细节。
- 使用表地一部分而不是整个表
- 保护数据:可以授予用户访问表地特定部分的权限,而不是整个表的访问权限。
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
性能问题
因为视图不包含数据,所以每次使用视图时,都必须处理查询执行时需要的所有检索。如果你用多个联结和过滤创建了复杂的视图或嵌套了视图(用视图1的数据创建视图2),那性能可能会下降地很厉害。
创建视图
1 |